Data nightmares and dreams [Datata #6]
Data is great, but also messy by nature. Do you even know where your data is at? Can we really control it?
![Data nightmares and dreams [Datata #6]](https://images.unsplash.com/photo-1611453210667-f1d26b30508f?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=MnwxMTc3M3wwfDF8c2VhcmNofDE3fHxtZXNzfGVufDB8fHx8MTYzMDMwNDUwMQ&ixlib=rb-1.2.1&q=80&w=1200)
Data is everywhere, it can make our life easier, but not always. Poor and missing data is arguably one of the biggest productivity killers. Data often contains information that is critical to the work/activities we do, so if that is wrong, we need to spend extra time.
Datum is a value stored in a location and more than one datum makes data. We have gone from using rocks to books to hard drives to store it. It is easier than ever to duplicate data, and that of course can create many problems. Imagine, contradictory information online about opening times of a restaurant. Which one do you trust?
“Without a systematic way to start and keep data clean, bad data will happen.” — Donato Diorio
Where is my data?
Have you ever thought about the quality of your own data? As humans there is a lot of information related to us: Address, phone number, name, ID number, blood type etc.
Information can end up in many different places such as: online services we sign up for, our friends´ memory, scattered notes, etc. In an attempt to understand the sheer number of places data about us is stored I took about 30 online services and checked individually which data points and which data they contain. Due to the manual nature of this task, I just took 30, the ones I have used in the last 3 months (according to my password manager).
To take an example: the phone number. This can change over time. In my graph 10 online services contain my phone number, some of them even up to 3 different phone numbers. Phone number can be used to communicate important information thus, for relevant services it is good to update it.
Often, we use a reactive approach. Whenever we detect a problem, we try to react instead of acknowledging, that if we change the phone number, we need to update the data to avoid problems in the first place.
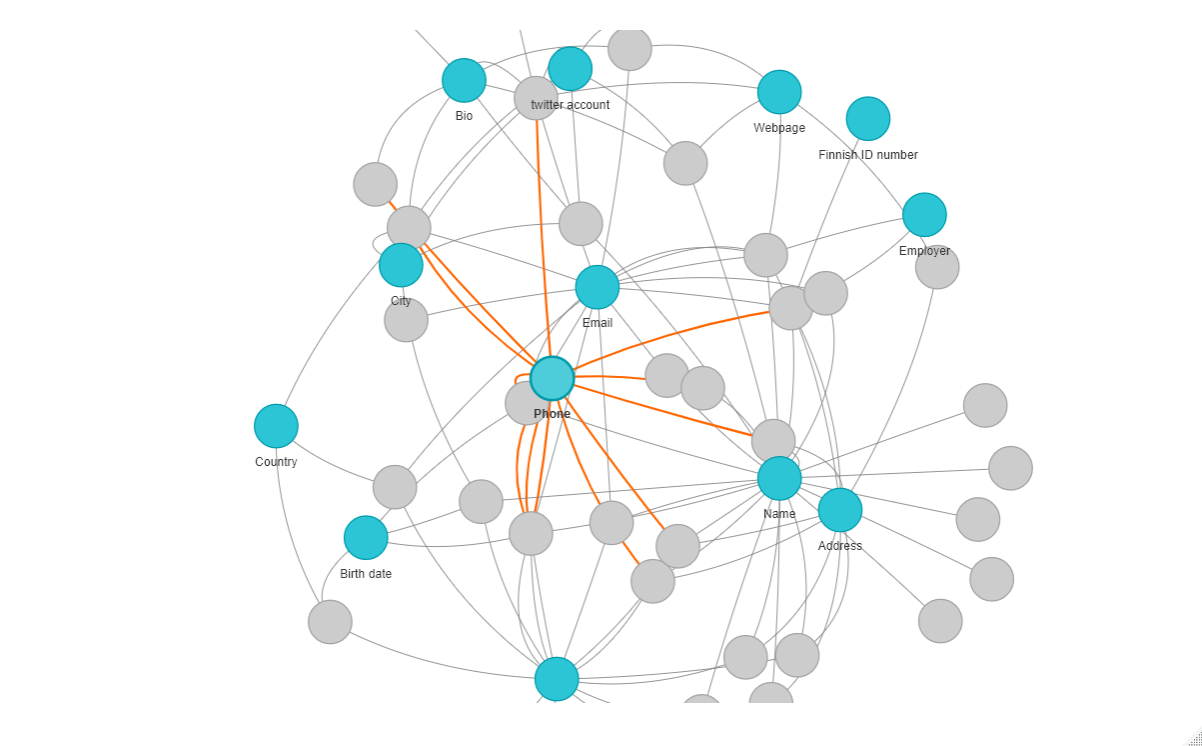
Similar with addresses, especially with the surge of online purchases, you don't want your package arriving at the wrong address. In the best of cases, you have the contact of the people living in your previous house or otherwise you might lose you package. In Finland for example it is important to inform the local post company about address changes as they cascade the updated information to various services serving as a central point, which makes the process easier.
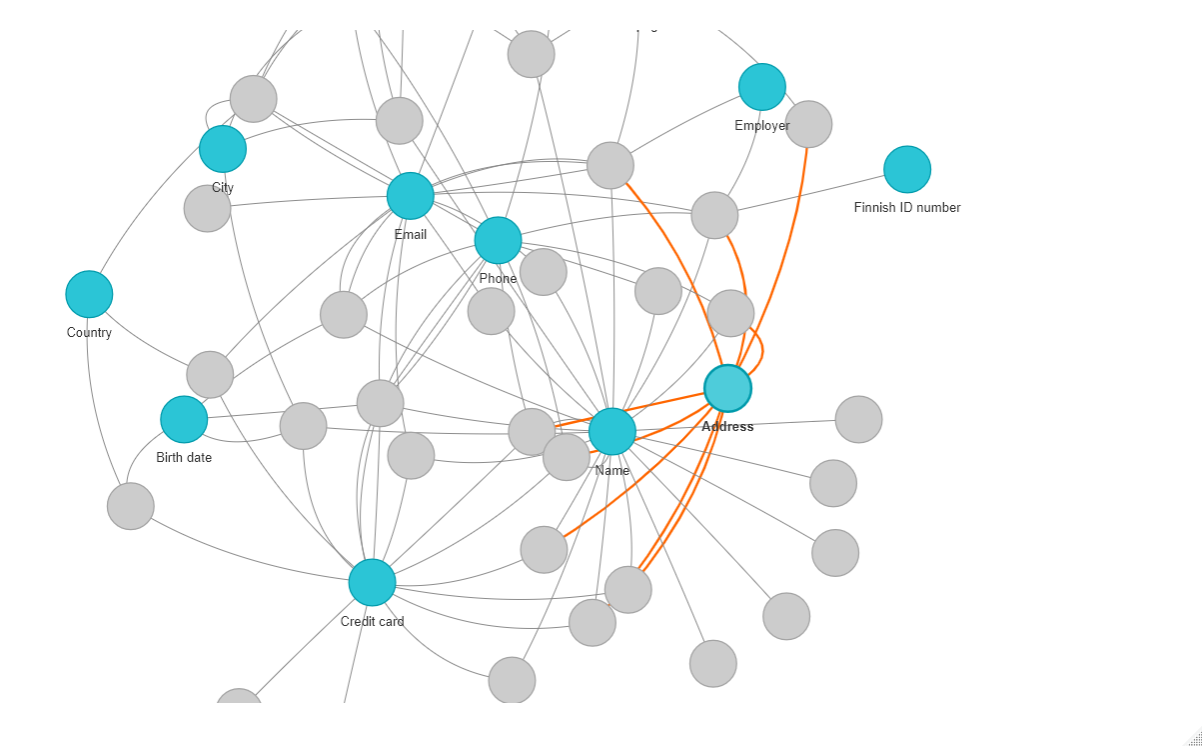
If there is a piece of information that services love it is your credit card information. This is the one that most likely they will take the extra mile if they find a problem with the payment, so you will know that either your card is expired or not active anymore.
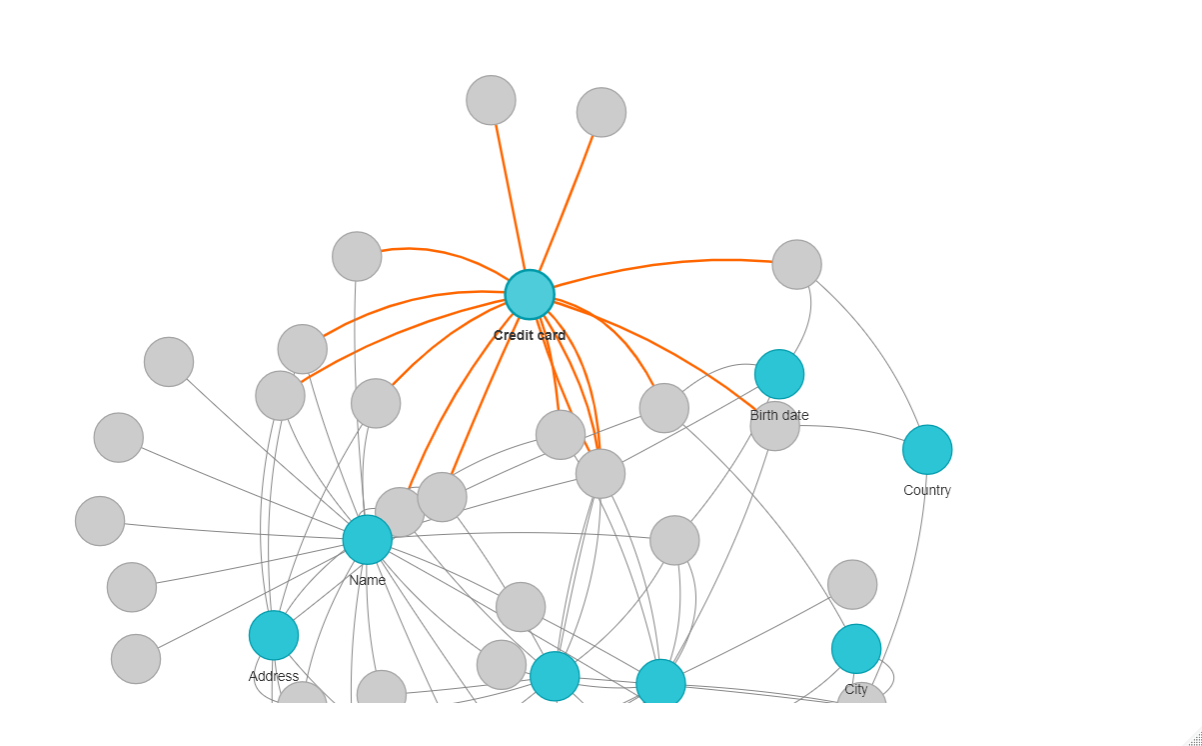
These graphs are taking only online services, but to get the big picture I would need for example to know how many friends have saved my phone number in their agendas, or written down my address. I don't necessarily have access to that data, but it can create issues if they don't update it properly. Also, how would they know you changed your phone or address unless you tell them?
It is already tricky just for an individual to really have control over your data/information. Now imagine for a company with thousands of employees, suppliers and customers. And millions of data points. Unless you have an approach to control the data many problems will arise: not updated prices leading to profitability loses, invoices that go to inactive emails, purchasing inactive components, contradicting data and so on.
Data governance to the rescue
Bad quality data shakes confidence and trust of users. Data governance is a rather new approach to govern the data by defining clear responsible for certain data, clear definitions and specific processes.
This is by no means an easy task, and it requires a dedicated team of professionals that will probably be having data nightmares at night.
One of the most surprising things for me when trying to get management buy-in for data governance was the difficulty to make definitions related to data. To put one example: Scoring a goal in football, how do you define who makes a goal?
Sounds pretty straight-forwards but what happens if the ball hits the defense before entering the net? Where is the limit between goal or own goal?
I have no answer for that, but seems like there isn't official rules to determine it.
This is just a simple example, but goes to show how difficult is often to define the data, specially at the edge cases.
The goal is to have consistent, accurate and complete data with integrity. That is the dream anyways. Easier said than done.
It is difficult enough to have a working data governance program in your company, but then comes the second nightmare, sharing data with others.
Sharing is caring?
When it comes to sharing data with other involved parties there are a lot of things to take into account, like who has access to what? How will we send updated data, yearly or when changes happen? Do they even use the same definition for a data point?
For example, delivery times might be measured differently by different companies, you could take the time from order to delivery, or from shipping to arrival, which gives you different numbers. You need to be clear over what is that you are exactly providing to them.
We shouldn't forget about the technical aspect to sharing data, in the best of cases we have a modern API where they can directly take the data they need, ensuring data is updated. In worst case, as you might have experienced: Here is the excel with updated info. That excel often arrives to people without much technical skills, which ends up in people changing data manually in their systems, even 100s and 1000s of lines. I have even seen PDF files with a table with data. Sure, thanks. Why don't you make it scanned to make my life easier?
You don't even need to be a big company to find yourself in this kind of problems. While data is an asset that is key for decision making, I am under the general impression that not enough effort is put into making sure the data is correct and the processes in place are good.
I agree with Steph Smith, in that we will see many chief automation officers and automation specialists that help companies automatize as much data sharing/processes between companies/software as possible, in order to free up workers time to do the most value adding jobs.
I 100% agree with Steph. pic.twitter.com/HnR8cormQM
— Sam Parr ⚪️ (@theSamParr) August 12, 2021
Personal data utopia
I have been talking about data nightmares, but what about data sweet dreams?
Imagine, that you would have just 1 central place where you update your personal information, and you can control who has access to what. So that they can just fetch the latest up-to-date data every time they need to use it.
This is probably just a utopia, since there would need to be certain standards so that internet services don't need to create millions of integrations. Really good security is also critical in order to protect personal data.
Some people have been working with this idea, for example Daniel Fang, offers an own API with some of his data. So, if you go to https://api.danielfang.org you can see his phone number, current work, projects etc.
This can be used to just feed the data in multiple webpages/platforms from a centralized place, but it could be used also for example so that your friends could find your updated address without them having to ask you.
Conclusion
A lot is discussed about how data is the future, AI etc. But data has its own life, what the data means might evolve over time, it will go hopping from one database to another and some of it will be lost in the way.
It is really difficult to be in control of the data, especially if you don't have any tools/processes to prevent bad data. Because I ensure you that it will happen eventually. Minimizing your data nightmares takes a proactive approach.
Is not sexy data work, but as necessary (or even more) for companies as using the latest Machine learning algorithms. What are you doing to get out of the data chaos?
You are not doing anything? Good luck, you will need it.